Complex Text Layout
Overview
Text in languages of the western world based on the Latin, Cyrillic, and Greek scripts is visualized pretty much like the way it is stored as data - from left to right, and each character corresponds to a single display symbol. We define such text as simple since the stored data requires less processing to be visualized. Not all the languages of the world have these characteristics. Text in languages of the eastern world (like Arabic, Hebrew, Urdu, Farsi, and so on) has a different presentation from the way it is stored as data - from right to left and characters that correspond to different symbols depending on surrounding characters. There is nothing in these languages themselves that is more complex than in the Latin-based languages, but we define them as complex since they require more processing in order to be visualized from the stored data.
How to use
Cohtml will automatically pick the most optimal way to process the text by scanning it for any complex characters. Using complex text comes at a slight performance cost and should be considered when designing the UI.
Details
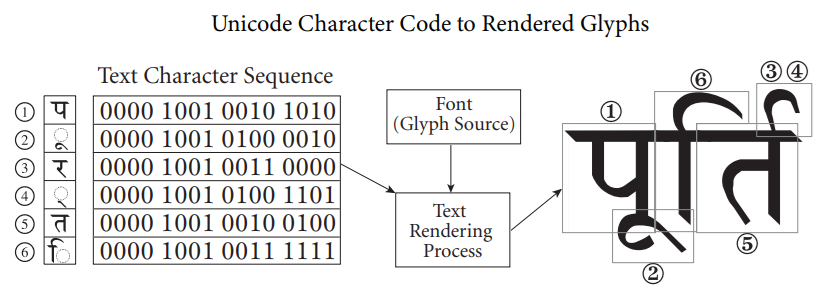
As mentioned above, certain Unicode character symbols will be visualized as multiple glyphs on screen and certain combinations of Unicode characters will be visualized as a single glyph on screen. Cohtml currently handles the drawing path correctly - converting from Unicode data to glyphs on screen. The support for the reverse path is limited and Cohtml may fail to properly pinpoint which Unicode character corresponds to a pixel on screen. Due to this limitation, the following features may work incorrectly:
- Caret movement and placement for input and text area fields
- Text selection highlight
- caretPositionFromPoint DOM API result